Сразу оговорюсь, дальше идёт практически эталонный образец бесполезной микрооптимизации. Бессмысленной и беспощадной, ибо сказано: «premature optimization is the root of all evil».
Тем не менее.
Приспичило давеча сделать банальнейшую вещь: затереть строчку пробелами. Иными словами, получив на вход строку, вернуть строку пробелов той же длины. Происходит это при замене жабаскриптом регулярного выражения, поэтому вызываться может многократно, откуда и проистекает естественное желание сделать это побыстрее.
Казалось бы, что может быть проще: взять у строки длину и выдать пробелы в нужном количестве. Оказывается, в жабаскрипте это – целая проблема, вызывающая бурные обсуждения. Дело в том, что в силу врождённой убогости, жабаскрипт не имеет сколько-нибудь развитых средств работы с текстом, то есть аналога перлового " "x10, равно как и наскального " "*10, там попросту нет. Простейший цикл с должным количеством конкатенаций упирается в крайне низкую производительность работы со строками.
Народное творчество на эту тему получило развитие в двух направлениях. Первый вариант, более удобный для написания, базируется на операции объединения пустых элементов массива заданной длины с размножаемой строкой в качестве разделителя. Второй вариант, быстрее работающий, построен на побитовом разложении числа повторений, удвоении длины путём объединения строки с самой собой, и добавлении дополнительной копии подстроки при установленном бите в числе повторений. Звучит страшно, выглядит так же, зато работает с логарифмической сложностью.
Все эти варианты, и многие другие, можно посмотреть, например, тут: http://stackoverflow.com/questions/202605/repeat-string-javascript. На мой взгляд, глубоко неправилен уже сам факт того, что примитивная потребность способна вызывать настолько развёрнутую дискуссию, но не будем о грустном.
Некоторое отличие нашей задачи от обсуждаемой там состоит в том, что у нас уже имеется строка нужной длины, и нам заранее известно то, чем её надо затирать. Это позволяет рассмотреть ещё несколько специфических для этого случая вариантов.
Один из них – дословно «затереть пробелами»: заменить каждый символ пробелом. Табличной подстановки на манер перлового tr/// в жабаскрипте нет, да и простая замена подстроки срабатывает только однократно, но есть замена по регэкспу, в том числе с глобальным модификатором: str.replace(/./g, ' ');
Другой вариант заключается в накоплении стратегического запаса пробелов, и выделения из них части по требованию: spaces.substr(0, str.length);
Устраивать тараканьи бега кусочков жабаскрипта в наше время можно с комфортом, для этих целей существует целый сервис http://jsperf.com, которым я не преминул воспользоваться.
Результат, в целом, предсказуем: регэкспы ожидаемо медленны, побитовая конкатенация ожидаемо быстра. Что любопытно, получение подстроки из большой строчки пробелов на порядок быстрее всего остального. Вероятно, современные жабаскриптовские движки не заморачиваются на копирование данных при получении подстрок, и ограничиваются созданием объектов ссылающихся в тот же буфер. Из чего можно сделать далеко идущие выводы: переменная с полученной из большого буфера небольшой подстрокой может мешать сборщику мусора утилизировать весь буфер. Если, конечно, такие случаи отдельно не отрабатываются. Теоретически с этим можно бороться, добавляя .valueOf() после .substring().
В нашем случае это только на руку: несмотря на то, что запас пробелов занимает ощутимое место, общее потребление памяти может быть даже контринтуитивно ниже, просто потому что все полученные строчки с пробелами помещаются внутри него, а во всех остальных вариантах каждая из них хранится отдельно.
При всех своих достоинствах, стратегический запас пробелов всё-таки конечен. На затирание очень большой строки его может просто не хватить. Следующий забег был посвящён поиску оптимального способа обработки больших строк. С подробностями и результатами можно ознакомиться здесь: http://jsperf.com/erase-string-with-spaces.
По смыслу задачи такие случаи не должны быть частыми, поэтому вариант «выдать большинство строк мгновенно из буфера, а большие отдельно склеить подольше» вполне имеет право на жизнь. При скрещивании получены несколько вариантов размножения строки самого буфера предыдущими способами с добиванием остатка подстрокой из него же.
Как ни странно, во всех протестированных браузерах кроме IE11 (показанного как other) скорость этого гибридного подхода (substr2, substr3) уступила побитовой конкатенации (repeat).
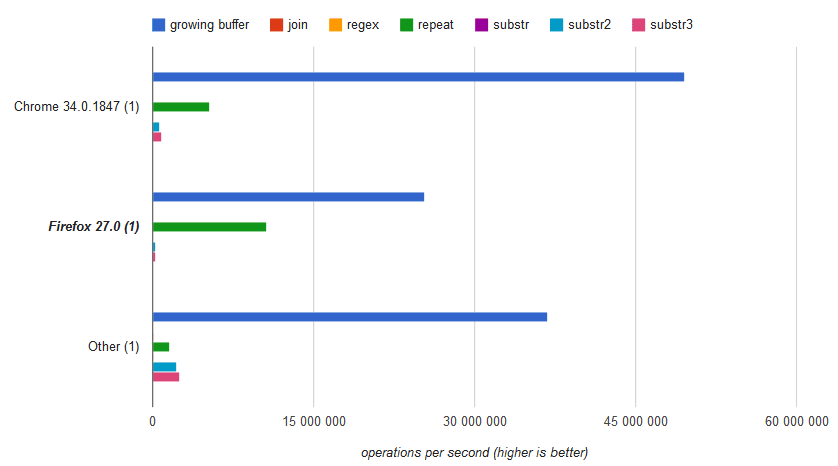
Поэтому, памятуя о том, что память всё равно разделяется всеми строчками, был добавлен вариант неограниченного увеличения буфера пробелов, и получения подстрок из него. На гистограмме он показан синим цветом. На больших строчках он отрабатывает многократно быстрее всех остальных вариантов, на мелких – незначительно медленнее получения подстрок из статического буфера.
Так что победителем этих тараканьих бегов объявляется следующая функция:
var spaces = " ";
function erase(str){
while(spaces.length < str.length) spaces += spaces;
return spaces.substr(0, str.length);
}
И да, она может сожрать вдвое больше памяти, чем надо. А может и не сожрать.